데이터베이스의 기본
데이터베이스의 기본
`데이터베이스(DB, DataBase)` 는 일정한 규칙, 혹은 규약을 통해 구조화되어 저장되는 데이터의 모음이다.
`DBMS (DataBase Management System)` 은 해당 데이터베이스를 제어, 관리하는 통합 시스템이다.
- 데이터베이스 안에 있는 데이터들은 특정 DBMS마다 정의된 쿼리 언어(query language)를 통해 삽입, 삭제, 수정, 조회 등을 수행할 수 있다.
- 데이터베이스는 실시간 접근과 동시 공유가 가능하다.
엔티티(entity)
엔티티는 사람, 장소, 물건, 사건, 개념 등 여러 개의 속성을 지닌 명사를 의미한다.
예를 들어 회원이라는 엔티티가 있다고 가정하면, 회원은 이름, 아이디, 주소, 전화번호의 속성을 갖는다. 물론 이보다 많은 속성이 있지만 서비스의 요구 사항에 맞춰 속성이 정해진다.
약한 엔티티와 강한 엔티티
엔티티는 약한 엔티티와 강한 엔티티로 구분된다. 예를 들어, A가 혼자서는 존재하지 못하고 B의 존재 여부에 따라 종속적이라면 A는 약한 엔티티이고 B는 강한 엔티티다.
- ex) 방은 건물 안에만 존재하기 때문에 방은 약한 엔티티라고 할 수 있고, 건물은 강한 엔티티라고 할 수 있다.
릴레이션(relation)
릴레이션은 데이터베이스에서 정보를 구분하여 저장하는 기본 단위다.
- 엔터티에 관한 데이터를 데이터베이스는 릴레이션 하나에 담아서 관리한다.
- 릴레이션은 관계형 데이터베이스에서는 ‘테이블’이라고 하며, NoSQL 데이터베이스에서는 ‘컬렉션’이라고 한다.
테이블과 컬렉션
데이터베이스의 종류는 크게 관계형 데이터베이스와 NoSQL 데이터베이스로 나눌 수 있다.
이 중 대표적인 관계형 데이터베이스인 MySQL과 대표적인 NoSQL 데이터베이스인 MongoDB를 예로 들 수 있다. MySQL의 구조는 `레코드-테이블-데이터베이스` 로 이루어져 있고, MonogoDB 데이터베이스의 구조는 `도큐먼트-컬렉션-데이터베이스` 로 이루어져 있다.
속성(attribute)
속성은 릴레이션에서 관리하는 구체적이며 고유한 이름을 갖는 정보다.
예를 들어, ‘차’라는 엔터티의 속성을 뽑자면, 차 넘버, 바퀴 수, 차 색깔, 차종 등이 있다. 이 중에서 서비스의 요구 사항을 기반으로 관리해야 할 필요가 있는 속성들만 엔터티의 속성이 된다.
도메인(domain)
도메인이란 릴레이션에 포함된 각각의 속성들이 가질 수 있는 값의 집합을 말한다.
예를 들어 성별이라는 속성이 있다면, 이 속성이 가질 수 있는 값은 {남, 여}라는 집합이 된다.
필드와 레코드

회원이라는 엔티티는 member라는 테이블로 속성인 이름, 아이디 등을 가지고 있으며 name, ID, address 등의 필드를 가진다. 그리고 이 테이블에 쌓이는 행(row) 단위의 데이터를 레코드라 하며, 튜플이라고도 한다.
필드 타입
필드는 타입을 갖는다. 예를 들어, 이름은 문자열이고 전화번호는 숫자인 것처럼 타입들은 DBMS마다 다르며, 여러 가지 타입이 있다. 대표적인 타입인 숫자, 날짜, 문자 타입이 있다.
- 숫자 타입: TINYINT, SMALLINT, MEDIUMINT, INT, BIGINT
- 날짜 타입: DATE, DATETIME, TIMESTAMP
- 문자 타입: CHAR, VARCHAR, TEXT, BLOB, ENUM, SET
관계
데이터베이스에 테이블은 하나만 있는 것이 아니다. 여러 개의 테이블이 있고 이러한 테이블은 서로의 관계가 정의되어 있다. 이러한 관계를 관계 화살표로 나타낸다.
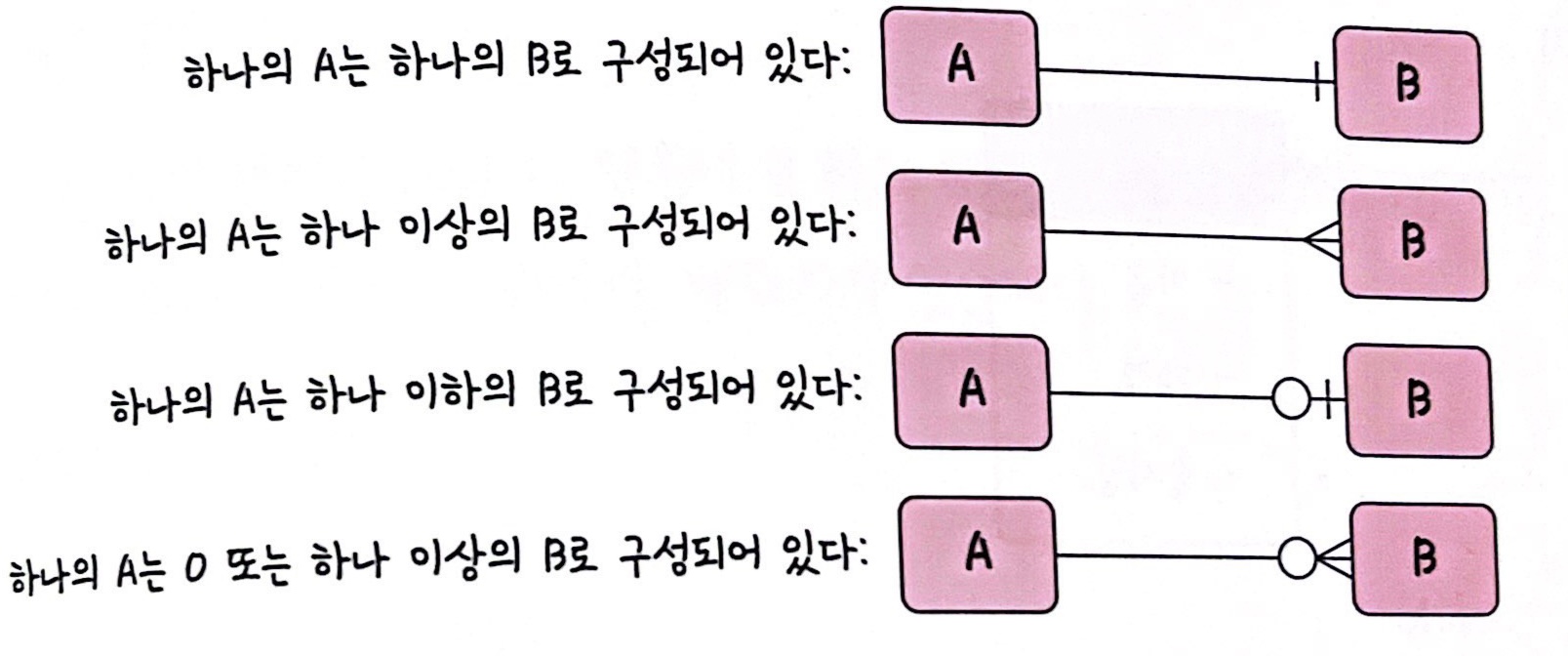
1:1 관계
예를 들어 유저당 유저 이메일 한개씩 있을 경우, 1:1 관계가 된다. 1:1 관계는 테이블의 두 개의 테이블로 나눠 테이블의 구조를 더 이해하기 쉽게 만들어 준다.
1:N 관계
예를 들어 쇼핑몰을 운영한다고 가정하면, 한 유저당 여러 개의 상품을 장바구니에 넣을 수 있다. 이 경우에도 1:N 관계가 된다. 물론 하나도 넣지 않는 0개의 경우도 있으니 0도 포함되는 화살표를 통해 표현해야 한다.
N:M 관계
학생과 강의 관계를 정의하면 학생이 강의를 많이 들을 수도 있고 강의도 여러 명의 학생들을 포함할 수 있다. 이 경우 N:M이 된다.
키
테이블 간의 관계를 조금 더 명확하게 하고 테이블의 자체의 인덱스를 위해 설정된 장치로 기본키, 외래키, 후보키, 슈퍼키, 대체키가 있다.
슈퍼키는 유일성이 있고, 그 안에 포함된 후보키는 최소성까지 갖춘 키다. 후보키 중에서 기본키로 선택되지 못한 키는 대체키가 된다. 유일성은 중복되는 값은 없으며, 최소성은 필드를 조합하지 않고 최소 필드만 써서 키를 형성할 수 있는 것을 말한다.
기본키(Primary Key)
기본키는 줄여 PK 또는 프라이머리키라고 많이 부르며, 유일성과 최소성을 만족하는 키다.
- 이는 테이블의 데이터 중 고유하게 존재하는 속성이며, 기본키에 해당하는 데이터는 중복되서는 안된다.
- 복합키를 기본키로 설정할 수 있지만, 그렇게 되면 최소성을 만족하지 못한다.
- 기본키는 자연키 또는 인조키 중에 골라 설정한다.
외래키(Foreign Key)
외래키는 FK라고도 하며, 다른 테이블의 기본키를 그대로 참조하는 값으로 개체와의 관계를 식별하는 데 사용한다.
- 외래키는 중복되어도 괜찮다.
후보키(Candidate Key)
후보키는 기본키가 될 수 있는 후보들이며 유일성과 최소성을 동시에 만족하는 키다.
대체키(Alternate Key)
대체키는 후보키가 두 개 이상일 경우 어느 하나를 기본키로 지정하고 남은 후보키들을 말한다.
슈퍼키(Super Key)
슈퍼키는 각 레코드를 유일하게 식별할 수 있는 유일성을 갖춘 키다.

{kind=link}
{kind=link}