복잡도
자료 구조(data structure)는 효율적으로 데이터를 관리하고 수정, 삭제, 탐색, 저장할 수 있는 데이터 집합을 말한다.
C++는 STL을 기반으로 전반적인 자료 구조를 가장 잘 설명할 수 있는 언어이며, 이를 기반으로 자료 구조에 대한 참고 코드를 제공한다.
> - STL
C++의 표준 템플릿 라이브러리이자 스택, 배열 등 데이터 구조의 함수 등을 제공하는 라이브러리의 묶음
복잡도
복잡도는 시간 복잡도와 공간 복잡도로 나뉜다.
시간 복잡도
C++의 기본
시간 복잡도를 알아보기 전, 잠시 C++의 기본을 살벼보자. 먼저 입력받은 문자열을 출력하는 프로그램을 하나 만들어 보자.
C++
#include <bits/stdc++.h> // --- (1)
using namespace std; // --- (2)
string a; // --- (3)
int main()
{
cin >> a; // --- (4)
cout << a << "\n"; // --- (5)
return 0; // --- (6)
}이렇게 만들고 실행시킨 이후 wow라고 입력하면 wow가 출력된다. 차근차근 설명해보면, C++는 main 함수를 중심으로 돌아가므로 main 함수 하나를 무조건 만들어야 한다. 이후 컴파일이 시작되면 전역변수 초기화, 라이브러리 import 등의 작업이 일어나고, main 함수에 얽혀 있는 함수들이 작동된다. 그러고 나서 main 함수가 0을 리턴하며 프로세스가 종료된다.
코드의 각 부분을 설명하면 다음과 같다.
1. 헤더 파일이다. STL 라이브러리를 import한다. 이 중 bits/stdc++.h는 모든 표준 라이브러리가 포함된 헤더이다. 2. std라는 네임스페이스를 사용한다는 뜻이다. cin이나 cout 등을 사용할 때 원래는 std::cin처럼 네임스페이스를 달아서 호출해야 하는데, 이를 기본으로 설정한다는 뜻이다. 참고로 네임스페이스는 같은 클래스 이름 구별, 모듈화에 쓰이는 이름을 말한다. 3. 문자열을 선언했다. <타입> <변수명> 이렇게 선언한다. string이라는 타입을 가진 a라는 변수를 정의했다. 예를 들어 string a = "큰 돌"이라고 해보자. 이때 a를 lvalue라고 하며 큰 돌을 rvalue라고 한다. lvalue는 추후 다시 사용되 수 있는 변수이며, rvalue는 한 번 쓰고 다시 사용되지 않는 변수를 말한다. 4. 입력이다. 대표적으로 cin, scanf가 있다. 5. 출력이다. 대표적으로 cout와 prinf가 있다. 6. return 0이다. 프로세스가 정상적으로 마무리됨을 뜻한다.
빅오 표기법
시간 복잡도란 '문제를 해결하는 데 걸리는 시간과 입력의 함수 관계'를 가리킨다. 어떠한 알고리즘의 로직이 '얼마나 오랜 시간'이 걸리는지를 나타내는 데 쓰이며, 보통 빅오 표기법으로 나타낸다. 예를 들어 '입력크기 n'의 모든 입력에 대한 알고리즘에 필요한 시간이 10n² + n이라고 하면 다음과 같은 코드를 상상할 수 있다.
C++
for (int i = 0; i < 10; i++) {
for (int j = 0; j < n; j++) {
for (int k = 0; k < n; k++) {
if (true) cout << k << '\n';
}
}
}
for (int i = 0; i < n; i++) {
if (true) cout << i << '\n';
}빅오 표기법이란 입력 범위 n을 기준으로 해서 로직이 몇 번 반복되는지 나타내는 것인데, 앞서 말한 코드의 시간 복잡도를 빅오 표기법으로 나타내면 O(n²)이 된다.
'가장 영향을 많이 끼치는' 항의 상수 인자를 빼고 나머지 항을 없앤 것이다. 다른 항들이 신경 쓰일 수도 있지만 증가 속도를 고려한다면 그러지 않다. 입력 크기가 커질수록 연산량이 가장 많이 커지는 항은 n의 제곱항이고, 다른 것은 그에 비해 미미하기 때문에 이것만 신경 쓰면 된다는 이론이다.
시간 복잡도의 존재 이유
이 시간 복잡도는 왜 필요할까? 바로 효율적인 코드로 개선하는 데 쓰이는 척도가 된다. 버튼을 누르고 화면이 나타나는데 이 로직이 O(n²)의 시간 복잡도를 가지고 9초가 걸린다고 해보자. 이를 O(n)의 시간 복잡도를 가지는 알고리즘으로 개선한다면 3초가 걸리게 된다.
시간 복잡도의 속도 비교
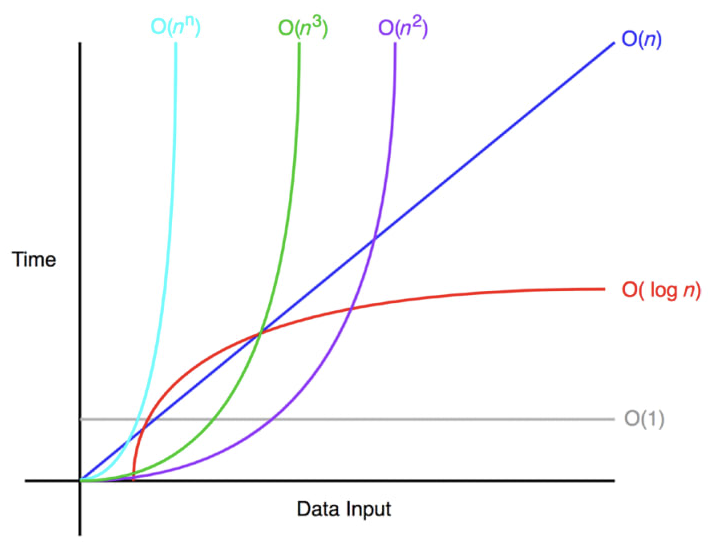
앞의 그림처럼 O(1)과 O(n)은 입력 크기가 커질수록 차이가 많이 나는 것을 볼 수 있다. O(n²)은 말할 것도 없을 만큼 차이가 크다. 즉, O(n²)보다는 O(n), O(n)보다는 O(1)을 지향해야 한다.
공간 복잡도
공간 복잡도는 프로그램을 실행시켰을 때 필요로 하는 자원 공간의 양을 말한다. 정적 변수로 선언된 것 말고도 동적으로 재귀적인 함수로 인해 공간을 계속해서 필요로 할 경우도 포함한다.
C++
int a[1004];예를 들어 앞의 코드처럼 되어 있는 배열이 있다고 하면 a 배열은 1004 x 4 바이트의 크기를 가지게 된다.
선형 자료 구조란 요소가 일렬로 나열되어 있는 자료 구조를 말한다.
연결 리스트
연결 리스트는 데이터를 감싼 노드를 포인터로 연결해서 공간적인 효율성을 극대화시킨 자료 구조이다. 삽입과 삭제가 O(1)이 걸리며 탐색에는 O(n)이 걸린다. 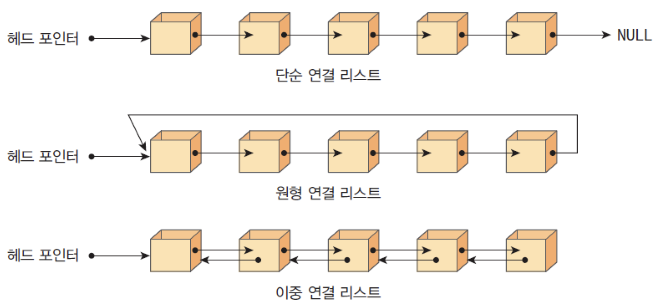
앞의 그림처럼 prev 포인터와 next 포인터로 앞과 뒤의 노드를 연결시킨 것이 연결 리스트이며, 연결 리스트는 단순 연결 리스트, 원형 연결 리스트, 이중 연결 리스트가 있다. 참고로 맨앞에 있는 노드를 헤드(head)라고 한다.
- 단순 연결 리스트 : next 포인터만 가진다.
- 원형 연결 리스트 : 이중 연결 리스트와 같지만 마지막 노드의 next 포인터가 헤드 노드를 가리키는 것을 말한다.
- 이중 연결 리스트 : next 포인터와 prev 포인터를 가진다.
배열
배열(array)은 같은 타입의 변수들로 이루어져 있고, 크기가 정해져 있으며, 인접한 메모리 위치에 있는 데이터를 모아놓은 집합이다. 또한, 중복을 허용하고 순서가 있다.
여기서 설명하는 배열은 '정적 배열'을 기반으로 설명한다. 탐색에 O(1)이 되어 랜덤 접근(random access)이 가능하다. 삽입과 삭제에는 O(n)이 걸린다. 따라서 데이터 추가와 삭제를 많이 하는 것은 연결 리스트, 탐색을 많이 하는 것은 배열로 하는 것이 좋다.
배열은 인덱스에 해당하는 원소를 빠르게 접근해야 하거나 간단하게 데이터를 쌓고 싶을 때 사용한다.
랜덤 접근과 순차적 접근
직접 접근이라고 하는 랜덤 접근은 동일한 시간에 배열과 같은 순차적인 데이터가 있을 때 임의의 인덱스에 해당하는 데이터에 접근할 수 있는 기능이다. 이는 데이터를 저장된 순서대로 검색해야 하는 순차적 접근과는 반대이다.
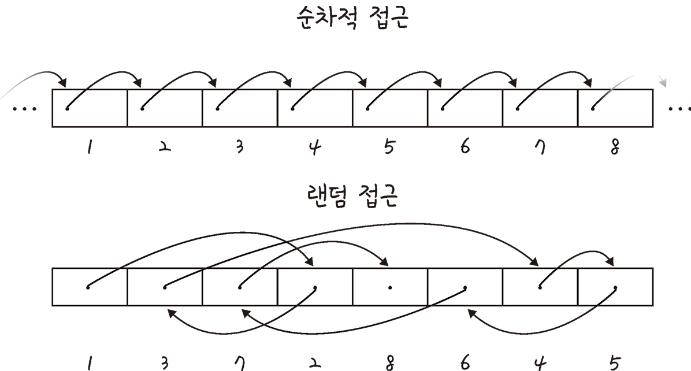
배열과 연결 리스트 비교
배열은 상자를 순서대로 나열한 데이터 구조이며 몇 번째 상자인지만 알면 해당 상자의 요소를 끄집어낼 수 있다.
연결 리스트는 상자를 선으로 연결한 형태의 데이터 구조이며, 상자 안의 요소를 알기 위해서는 하나씩 상자 내부를 확인해봐야 한다는 점이 다르다.
탐색은 배열이 빠르고 연결 리스트는 느리다. 배열의 경우 그저 상자 위에 있는 요소를 탐색하면 되는 반면에, 연결 리스트는 상자를 열어야 하고 주어진 선을 기반으로 순차적으로 열어야 한다.
하지만 데이터 추가 및 삭제는 연결 리스트가 더 빠르고 배열은 느리다. 배열은 모든 상자를 앞으로 옮겨야 추가가 가능하지만, 연결 리스트는 선을 바꿔서 연결해주기만 하면 되기 때문이다.
벡터
벡터(vector)는 동적으로 요소를 할당할 수 있는 동적 배열이다. 컴파일 시점에 개수를 모른다면 벡터를 써야 한다. 또한, 중복을 허용하고 순서가 있고 랜덤 접근이 가능하다. 탐색과 맨 뒤의 요소를 삭제하거나 삽입하는 데 O(1)이 걸리며, 맨 뒤나 맨 앞이 아닌 요소를 삭제하고 삽입하는 데 O(n)의 시간이 걸린다.
참고로 뒤에서부터 삽입하는 push_back()의 경우 O(1)의 시간이 걸리는데, 벡터의 크기가 증가되는 시간 복잡도가 amortized 복잡도, 즉 상수 시간 복잡도 O(1)과 유사한 시간 복잡도를 가지기 때문이다.
스택
스택은 가장 마지막으로 들어간 데이터가 가장 첫 번째로 나오는 성질(LIFO, Last In First Out)을 가진 자료 구조이다. 재귀적인 함수, 알고리즘에 사용되며 웹 브라우저 방문 기록 등에 쓰인다. 삽입 및 삭제에 O(1), 탐색에 O(n)이 걸린다. 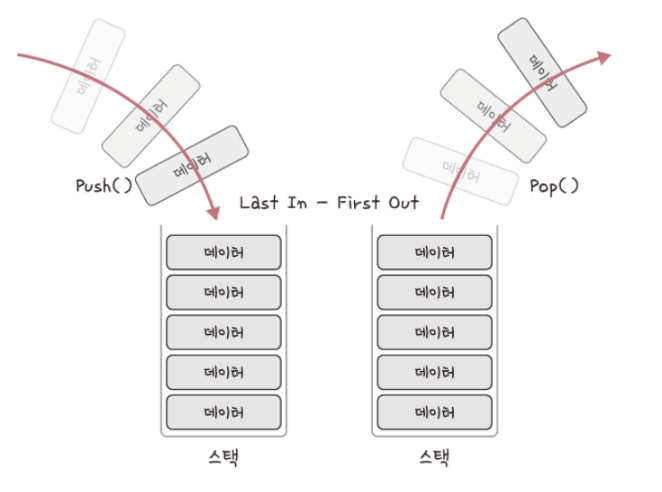
큐
큐(queue)는 먼저 집어 넣은 데이터가 먼저 나오는 성질(FIFO, First In First Out)을 지닌 자료 구조이며, 나중에 집어 넣은 데이터가 먼저 나오는 스택과는 반대되는 개념을 가졌다. 삽입 및 삭제에 O(1), 탐색에 O(n)이 걸린다. 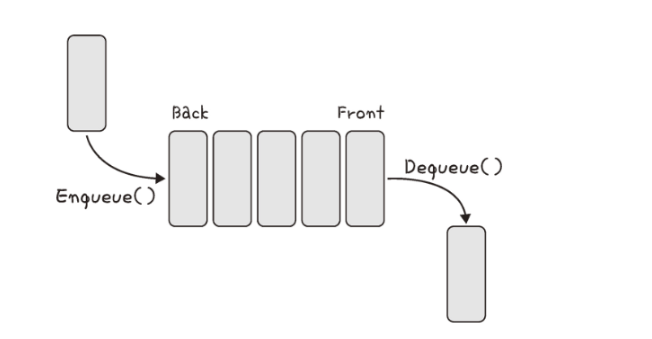

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}