인덱스와 조인
기술노트
인덱스와 조인
💡 인덱스
- 데이터를 빠르게 찾을 수 있는 하나의 장치
- 인덱스를 설정하면 테이블 안에 내가 찾고자 하는 데이터를 빠르게 찾을 수 있다.
- 일반적인 select 쿼리 실행 : 1. 메모리의 database buffer cache를 체크 2. buffer cache에는 자주 사용되는 테이블들이 캐싱되어 있어 여기에 데이터가 있을 경우 바로 찾아 출력하고 없을 경우 하드디스크에 있는 데이터 파일에서 데이터를 찾음 - 인덱스를 사용하면 이런 과정을 거치지 않고 바로 주소를 통해 찾아간다.
💡 인덱스의 생성 원리
- 먼저 해당 테이블을 모두 읽는다.
- 인덱스를 만드는 동안 데이터가 변경되면 문제가 되므로 해당 데이터들이 못하도록 조치한 후 메모리(PGA의 Sort Area)에서 정렬
💡 인덱스의 동작 원리
- 데이터 파일의 블록이 10만개가 있다고 가정할때 select문 실행시
- 1. server process가 구문분석과정을 마친후 database buffer cache에 조건에 부합하는 데이터가 있는지 확인
- 2. 해당 정보가 buffer cache에 없다면 디스크 파일에서 조건에 부합하는 블럭을 찾아 database buffer cache에 가져온 뒤 사용자에게 보여줌
- 이 경우 index가 없으면 10만개 전부 database buffer cache로 복사한뒤 풀스캔으로 찾게됨
- index가 있으면 where절의 조건의 컬럼이 index의 키로 생성되어있는지 확인한 뒤, 인덱스에 먼저 가서 조건에 부합하는 정보가 어떤 ROWID를 가지고 있는지 확인 후 ROWID에 있는 블럭을 찾아가 해당 블럭만 buffer cache에 복사
💡 B-트리
- 인덱스는 보통 B-트리라는 자료 구조로 이루어져 있다.
- `B-트리`는
- `루트 노드` - 루트 노드와 리프 노드 사이에 있는 `브랜치 노드` - `리프 노드`
💡 인덱스가 효율적인 이유와 대수확장성
- 인덱스가 효율적인 이유
→ 효율적인 단계를 거쳐 모든 요소에 접근할 수 있는 균형 잡힌 `트리 구조`와 `트리 깊이`의 대수확장성 때문이다.
- 대수확장성 : 트리 깊이가 리프 노드 수에 비해 매우 느리게 성장하는 것
- 기본적으로 인덱스가 한 깊이씩 증가할 때마다 최대 인덱스 항목의 수는 4배씩 증가한다.
💡 인덱스를 만드는 방법
💡 MySQL
- 클러스터형 인덱스
- 테이블당 하나를 설정 가능 - `primary key` 옵션으로 기본키를 만들면 클러스터형 인덱스를 생성할 수 있고, - 기본키로 만들지 않고 `unique not null` 옵션을 붙이면 클러스터형 인덱스로 만들 수 있다.
- 세컨더리 인덱스
- 보조 인덱스로 여러 개의 필드 값을 기반으로 쿼리를 많이 보낼 때 생성해야 하는 인덱스 - `create index...` 명령어를 기반으로 만들 수 있다. - 하나의 인덱스만 생성할 것이라면 클러스터형 인덱스를 만드는 것이 성능이 좋다.
> 예를 들어 age라는 하나의 필드만으로 쿼리를 보낸다면 클러스터형 인덱스만 필요하다. 하지만 age, name, email 등 다양한 필드를 기반으로 쿼리를 보낼 때는 세컨더리 인덱스를 사용해야 한다.
💡 MongoDB
- 도큐먼트를 생성 시 자동으로 ObjectID가 형성
→ 해당 키가 기본키로 설정
- 세컨더리키도 부가적으로 설정 가능
→ 기본키와 세컨더리키를 같이 쓰는 복합 인덱스 설정 가능!
💡인덱스의 장단점
💡 인덱스 최적화 기법
1. 인덱스는 비용이다
- 인덱스는 두 번 탐색하도록 강요한다.
→ 인덱스 리스트, 그다음 컬렉션 순으로 탐색하기 때문이며, 관련 읽기 비용이 들게 된다.
- 컬렉션이 수정되었을 때 인덱스도 수정되어야 한다.
- 책의 본문이 수정되었을 때 목차나 찾아보기도 수정해야 하듯이! - 이때 B-트리의 높이를 균형 있게 조절하는 비용도 들고, 데이터를 효율적으로 조회할 수 있도록 분산시키는 비용도 들게 된다. - 그렇기 때문에 쿼리에 있는 필드에 인덱스를 무작정 다 설정하는 것은 좋지 않다.
- 컬렉션에서 가져와야 하는 양이 많을수록 인덱스를 사용하는 것은 비효율적이다.
2. 항상 테스팅하라
- 인덱스 최적화 기법은 서비스 특징에 따라 달라진다.
→ 서비스에서 사용하는 객체의 깊이, 테이블의 양 등이 다르기 때문이다.
- 따라서 항상 테스팅하는 것이 중요하다.
- explain() 함수를 통해 인덱스를 만들고 쿼리를 보낸 이후에 테스팅을 하며 걸리는 시간을 최소화해야 한다.
3. 복합 인덱스는 같음, 정렬, 다중 값, 카디널리티 순이다
- 보통 여러 필드를 기반으로 조회를 할 때 복합 인덱스를 생성한다.
- 이 인덱스를 생성할 때는 순서가 있고 생성 순서에 따라 인덱스 성능이 달라진다. - 같음, 정렬, 다중 값, 카디널리티 순으로 생성해야 한다.
💡 조인
- 하나의 테이블이 아닌 두 개 이상의 테이블을 묶어서 하나의 결과물을 만드는 것
- MySQL에서는 JOIN이라는 쿼리, MongoDB에서는 lookup이라는 쿼리로 이를 처리할 수 있다.
- _but, MongoDB를 사용할 때 lookup은 되도록 사용하지 말아야 한다. MongoDB는 조인 연산에 대해 관계형 데이터베이스보다 성능이 떨어진다고 여러 벤치마크 테스트에서 알려져 있다._
- 따라서 여러 테이블을 조인하는 작업이 많을 경우 MongoDB보다는 관계형 데이터베이스를 써야 한다.
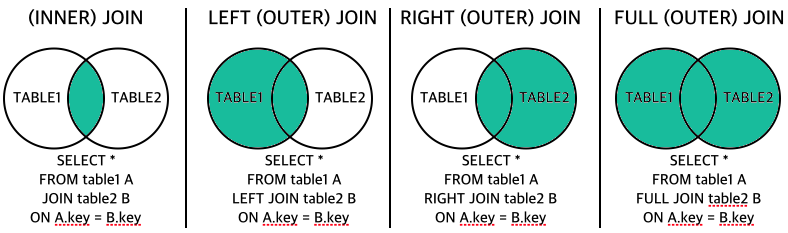
💡 조인의 종류
💡 내부 조인
- 왼쪽 테이블과 오른쪽 테이블의 두 행이 모두 일치하는 행이 있는 부분만 표기
→ 두 테이블 간에 교집합
sql
SELECT * FROM table1 A
INNER JOIN table2 B ON
A.key = B.key💡 왼쪽 조인
- 테이블 B의 일치하는 부분의 레코드와 함께 테이블 A를 기준으로 완전한 레코드 집합을 생성, 만약 테이블 B에 일치하는 항목이 없으면 해당 값은 null 값.
→ 왼쪽 테이블의 모든 행이 결과 테이블에 표기
sql
SELECT * FROM table1 A
LEFT JOIN table2 B ON
A.key = B.key💡 오른쪽 조인
- 테이블 A의 일치하는 부분의 레코드와 함께 테이블 B를 기준으로 완전한 레코드 집합을 생성, 만약 테이블 A에 일치하는 항목이 없으면 해당 값은 null 값.
→ 왼쪽 테이블의 모든 행이 결과 테이블에 표기
sql
SELECT * FROM table1 A
RIGHT JOIN table2 B ON
A.key = B.key💡 합집합 조인
- 합집합 조인(완전 외부 조인)
- 양쪽 테이블에서 일치하는 레코드와 함께 테이블 A와 테이블 B의 모든 레코드 집합을 생성, 이때 일치하는 항목이 없으면 누락된 쪽에 null 값.
→ 두 개의 테이블을 기반으로 조인 조건에 만족하지 않는 행까지 모두 표기
sql
SELECT * FROM table1 A
FULL OUTER JOIN table2 B ON
A.key = B.key💡 조인의 원리
💡 중첩 루프 조인
- 중첩 루프 조인(NLJ, Nested Loop Join)
- 중첩 for 문과 같은 원리로 조건에 맞는 조인을 하는 방법
→ 랜덤 접근에 대한 비용이 많이 증가하므로 대용량의 테이블에서는 사용하지 않는다.
- 중첩 루프 조인(BNL, Block Nested Loop)
- 중첩 루프 조인에서 발전 - 조인할 테이블을 작은 블록으로 나눠서 블록 하나씩 조인하는 방식
💡 정렬 병합 조인
- 각각의 테이블을 조인할 필드 기준으로 정렬하고 정렬이 끝난 이후에 조인 작업을 수행하는 조인
- 조인할 때 쓸 적절한 인덱스가 없고 대용량의 테이블들을 조인하며, 조인 조건으로 <, >등 범위 비교 연산자가 있을 때 쓴다.
💡 해시 조인
- 해시 테이블을 기반으로 조인하는 방법
- 동등(=)조인에서만 사용할 수 있다.
- 두 개의 테이블을 조인할 때 하나의 테이블이 메모리에 온전히 들어간다면 보통 중첩 루프 조인보다 더 효율적 (메모리에 올릴 수 없을 정도로 크다면 디스크를 사용하는 비용이 발생된다.)

{kind=link}